MLVehiclePriceAdvisor
Intro
MLVehiclePriceAdvisor is a Python-based project designed to scrape vehicle data from the popular automotive marketplace Otomoto. The data is then processed and used to train a random forest machine learning model to predict optimal vehicle pricing based on their features.
- The script extracts vehicle data from Otomoto and saves it into CSV files for each car brand.
- The project processes and cleans the data, preparing it for machine learning analysis.
- The random forest model predicts optimal vehicle prices based on attributes like mileage, production year, and engine power.
- A console application allows users to input vehicle details and receive price recommendations.
Features
- Vehicle data extraction
- Data preprocessing
- Random forest model
- Optimal price prediction
- Console application
- Python-based implementation
- CSV data storage
- Data cleaning
- Responsive predictions
- User-friendly interface
- Machine learning analysis
Technologies Used
 Python
Python Selenium
Selenium Pandas
Pandas
 Scikit-learn
Scikit-learn Joblib
Joblib
Demo
Data Scraping
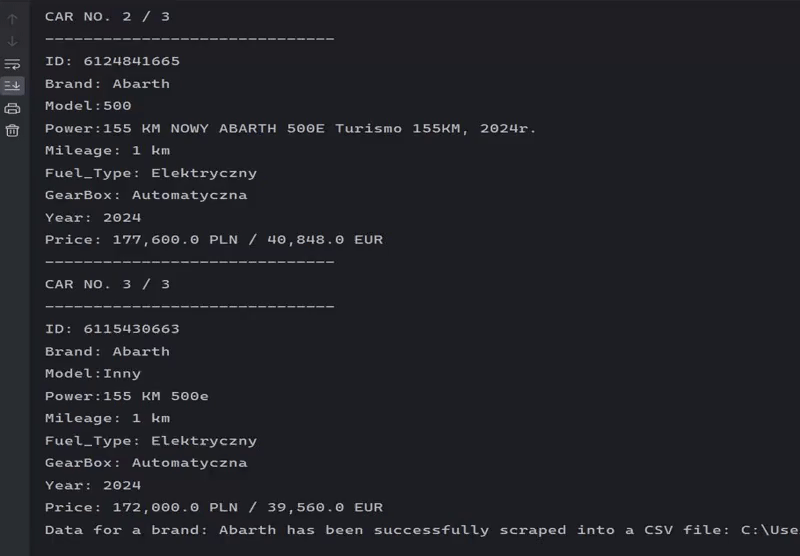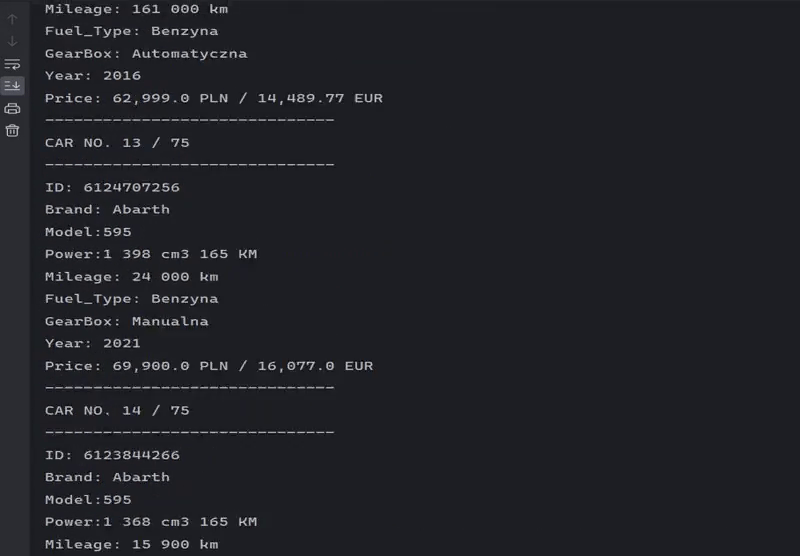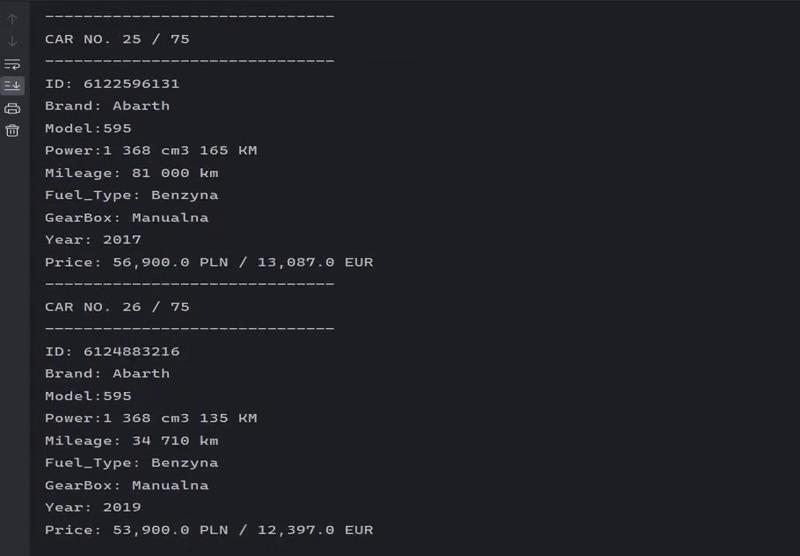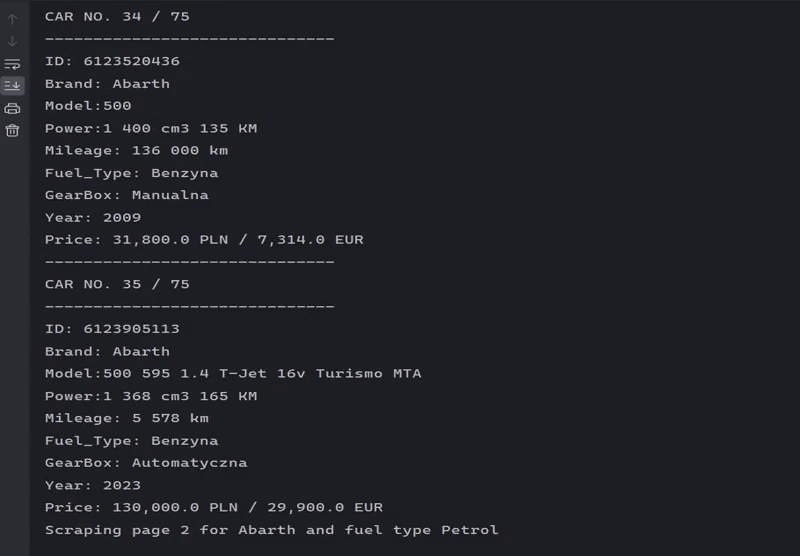
Scraping listings for a specific brand.
Checking if data has already been collected for a specific fuel type.
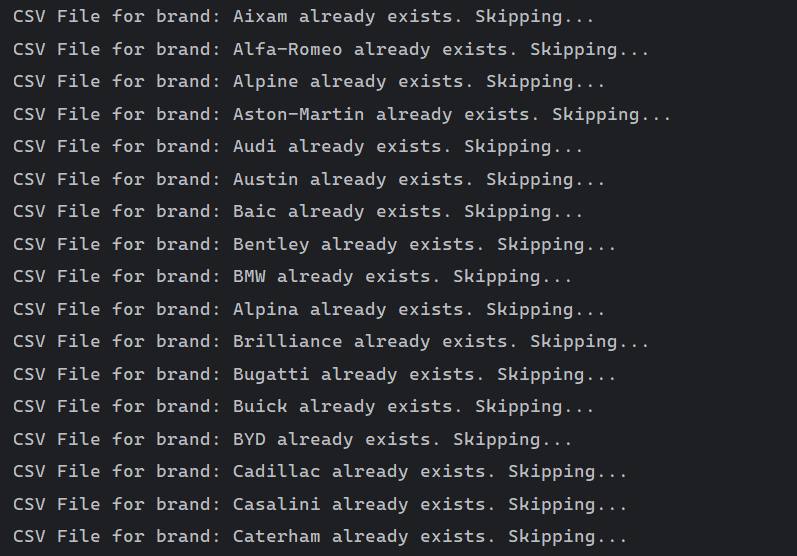
Skipping brands with existing CSV files to avoid duplicates.
Data Processing

Original dataset collected directly from Otomoto, containing raw and unprocessed data.
- Data Merging: Combines multiple CSV files from different car brands into one dataset.
- Invalid Data Removal: Removes invalid entries and non-numeric units (e.g., 'km', 'cm³', 'KM').
- Price Conversion: Converts prices to numerical format by removing commas and changing to floats.
- Consistency Check: Ensures all entries are formatted consistently.
- Data Conversion: Converts mileage, engine power, and prices to float format for consistency.
- Space Removal: Removes spaces and ensures all numeric fields are formatted correctly.
- Dataset Balancing: Adjusts dataset entries to ensure a balanced representation.
- Data Validation: Checks for missing or corrupted data entries.

Processed dataset, cleaned and formatted for machine learning analysis.
Model Training
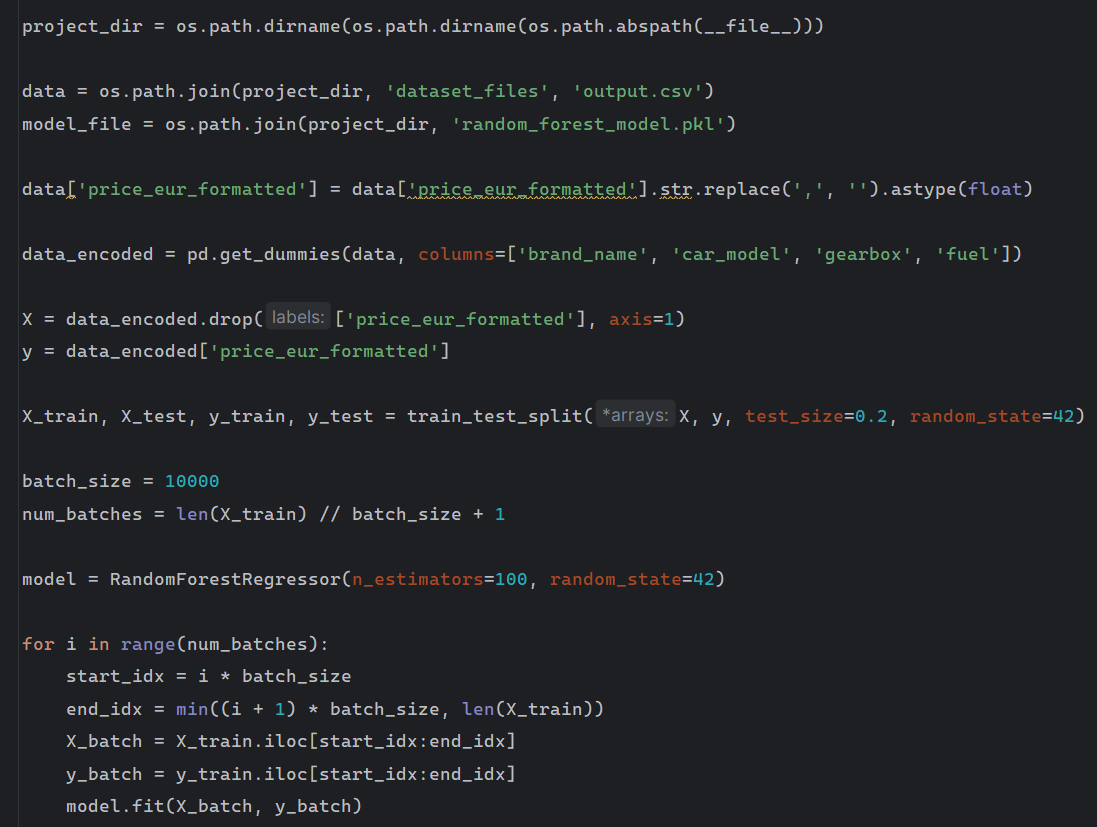
The RandomForest_Training.py script trains a Random Forest model to predict vehicle prices.
- Data Preparation: Loads data and converts price to numeric format.
- Feature Encoding: Categorical features such as 'brand_name', 'car_model', 'gearbox', and 'fuel' are converted to numerical format using one-hot encoding.
- Feature Selection: Input features
Xexclude the target price column, which is set as the outputy. - Data Splitting: Data is split into training (80%) and testing (20%) sets to validate model performance.
- Batch Training: Uses a batch size of 10,000 for efficient training on large datasets.
- Model Evaluation: The trained model returned an R² score of 0.81.
Price Prediction - Code Analysis
- Data Loading: The model and data are loaded from pre-saved files.
- Data Preprocessing: Converts prices to float and applies one-hot encoding for categorical features.
- Feature Engineering: Adjusts the predicted price based on mileage and production year.
- User Input Handling: The console application prompts the user for details such as brand, model, mileage, and production year.
- Data Validation: Ensures the user input data is complete and valid before proceeding with predictions.
- Price Prediction: The model predicts an initial price based on the provided vehicle details.
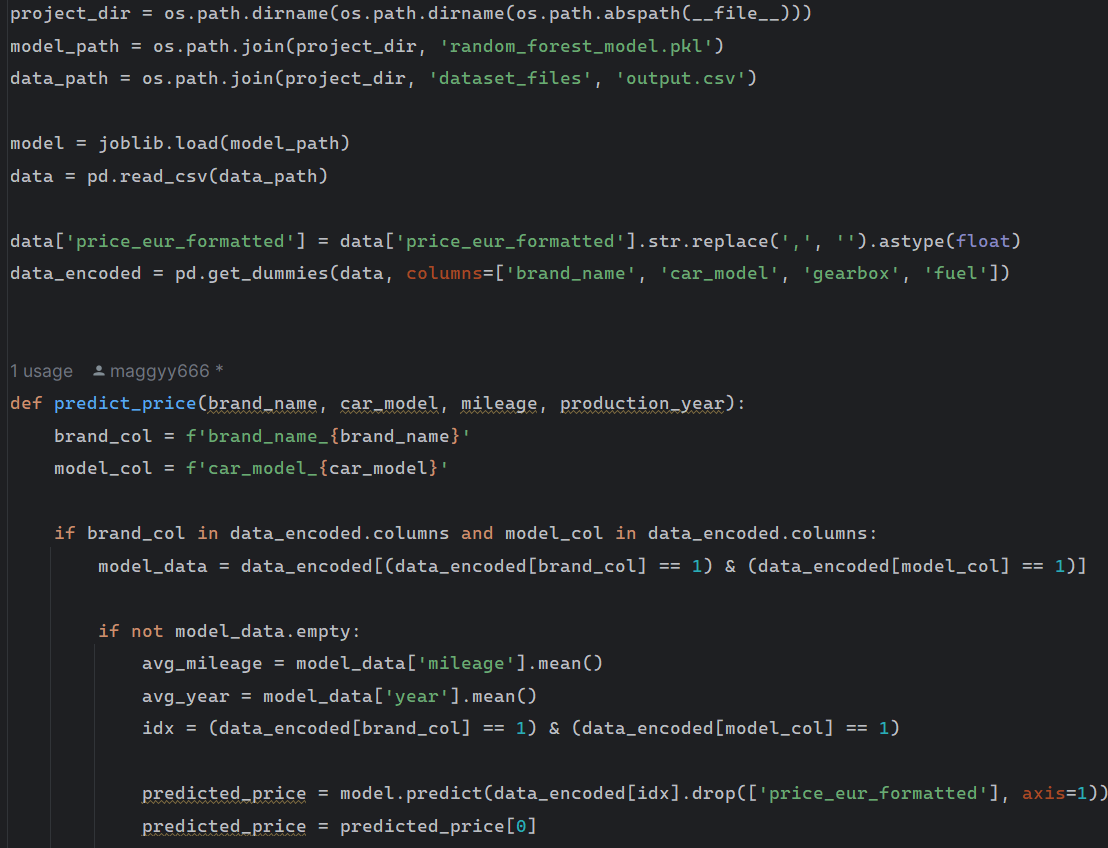
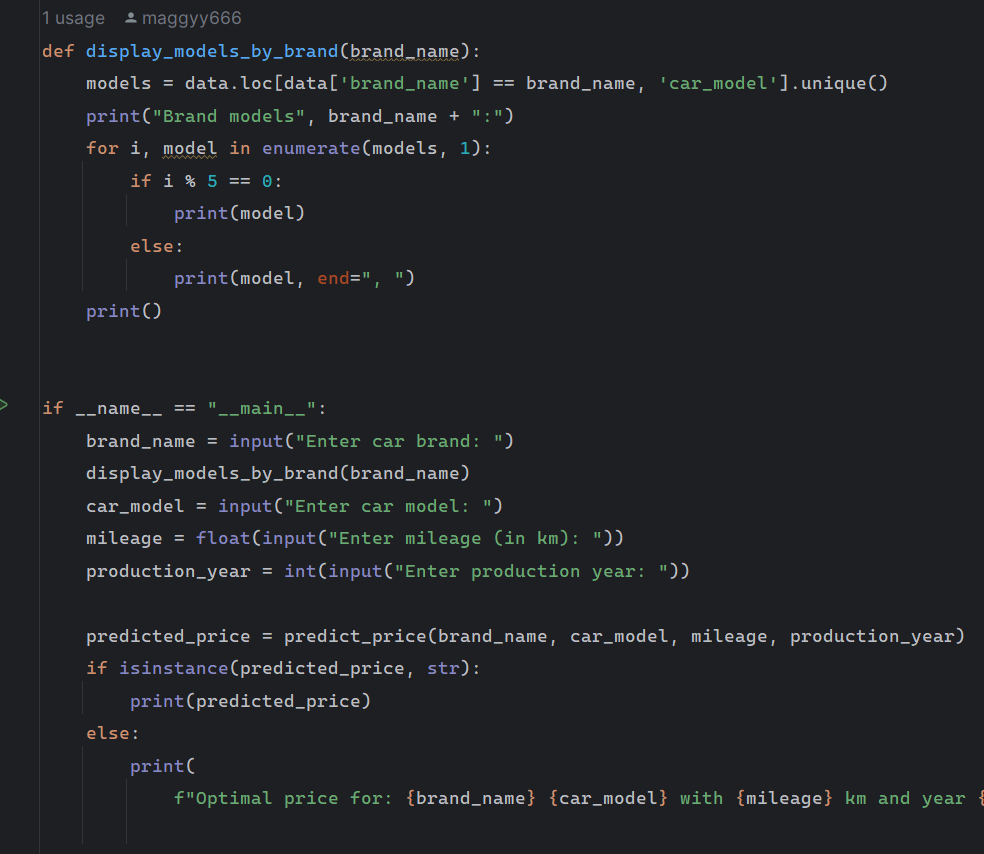
- Prediction Adjustment: The predicted price is adjusted iteratively based on the input mileage and production year.
- Comparison with Market Data: Compares the predicted price with similar listings on Otomoto to ensure accuracy.
- Final Output: The adjusted price is displayed to the user, providing an optimal pricing suggestion.
- User Interaction: The application provides feedback based on the availability of data for the specified make and model.
- Error Handling: Handles cases where the model cannot make a prediction due to insufficient data.
- Data Logging: Logs the user input and predicted prices for future analysis and model improvement.
Price Prediction
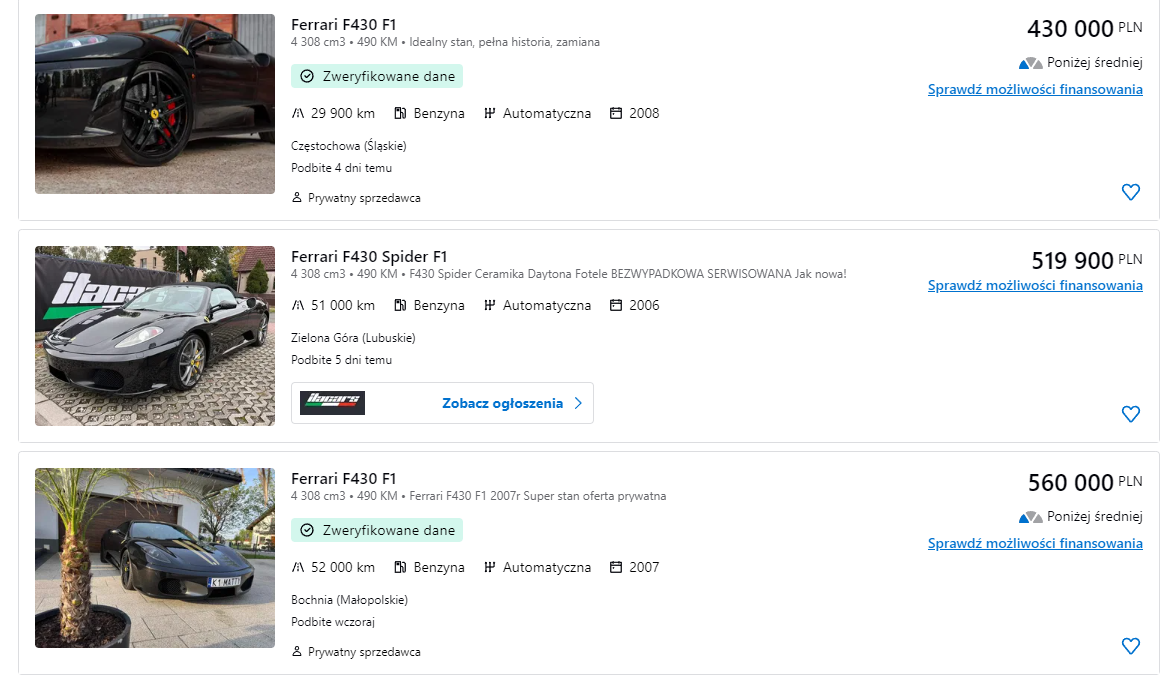
- Scenario: Input data matches the average range for existing data.
- Optimal Price: The model predicts an optimal price based on typical data points.
- User Input: Brand: Ferrari, Model: F430 F1, Mileage: 50000 km, Year: 2007.
- Result: The predicted price aligns with the average market price, suggesting a fair valuation.

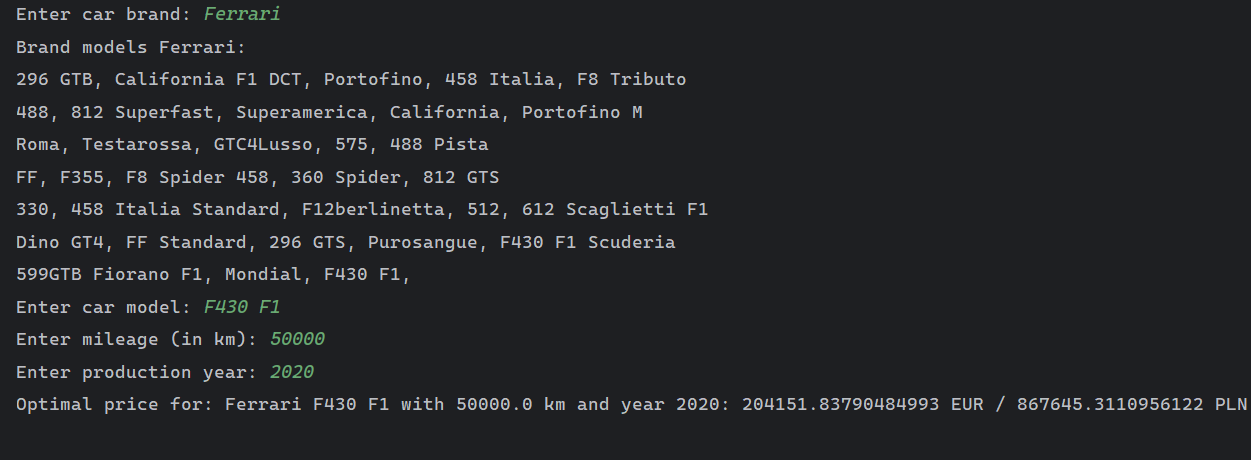
- Scenario: Input data exceeds typical range, representing a newer model year.
- Price Adjustment: The model adjusts the predicted price to reflect higher value for newer models.
- User Input: Brand: Ferrari, Model: F430 F1, Mileage: 50000 km, Year: 2020.
- Result: The predicted price is higher due to the newer model year, providing a realistic market estimation.
Source Code
You can view the source code: HERE